Gelişmelerden haberdar olmak için e-posta adresinizi giriniz.
Nacizane “AI Agent” konusunda topladığım notları paylaşacağım. Bu yazıda aşağıdaki sorulara yanıt bulabilirsiniz.
Günümüz yapay zekası, yalnızca metin üretmekle kalmıyor; aynı zamanda internetteki yüzlerce kaynağı tarayarak detaylı raporlar oluşturabilen, bağımsız çalışan "agent" sistemlerle de karşımıza çıkıyor. Örneğin, OpenAI'nin Deep Research aracı—bir araştırma analisti gibi çalışarak dakikalar içinde kapsamlı raporlar hazırlayabiliyor—bu teknolojinin ne kadar ileri gittiğini açıkça gözler önüne seriyor. Bu yazıda; yapay zekayı kullanarak nasıl ürün ortaya koyabileceğimizi, büyük dil modellerinin (LLM) temel prensiplerini, agent kavramının ne anlama geldiğini ve framework kullanmanın mı yoksa native geliştirme yoluyla mı ilerlemenin mi avantajlı olduğunu tartışacağız. Ayrıca, düşük bütçeyle (hatta ücretsiz) çeşitli agentlar oluşturup denemenin yollarını ve Google AI Studio API’a nasıl erişebileceğinizi adım adım inceleyeceğiz. Basitten karmaşığa “AI Agent” kodları yazacağız. Bu kodları yazarken Anthropic Tarafından önerilen workflow ve agent akış şemalarından faydalanacağız. Böylece, Deep Research gibi ileri seviye uygulamaların arkasındaki teknolojiyi hem teorik hem de pratik örneklerle keşfetmiş olacaksınız.
Bu süreç, klasik bir web sitesi yayınlamaktan farklı değildir. Ancak burada farkı oluşturan nokta, API istekleri yaptığımızda aldığımız sonuçların tutarlılığını sağlamak için eskisinden farklı yaklaşımlara ihtiyaç duymamızdır. Başvurduğumuz klasik API’ler, genellikle kod için güzel formatlanmış sonuçlar vermektedir. Bir LLM’e API isteğinde bulunduğumuzda, bu sonucu kodumuzda kullanabilmek için iyi bir prompt yazmalı ve girdileri istediğimiz sonuca uygun şekilde düzenlemeliyiz. Burada bahsettiğimiz süreç, LLM’i kara kutu (blackbox) olarak ele almaktadır. LLM geliştirmek ve onu yayınlamak ise tamamen ayrı bir süreçtir ve maliyetli GPU gücüne erişim gerektirir.
LLM kullanarak ürün ortaya koyma sürecine gelince, öncelikle çözmek istediğiniz problemi ve hedef kitlenizi belirlemeniz gerekir. Fikrinizi somutlaştırmak adına, LLM’in hangi görevleri yerine getireceğini—örneğin metin özetleme, içerik üretimi, öneri sistemi gibi—tanımlamalısınız. Bu aşamada, LLM API’lerinden gelen ham verileri nasıl işleyip uygulamanızın ihtiyacına uygun hale getireceğinizi planlamalısınız. Ardından, API istekleri için özenle hazırlanmış prompt’lar ile prototip oluşturma aşamasına geçersiniz.
Prototipinizi oluşturduktan sonra, backend tarafında API çağrılarını yöneten ve gelen verilerin doğruluğunu kontrol eden bir yapı kurarsınız. Bu aşamada, hata yönetimi, yanıtların ön işlenmesi ve veri bütünlüğünün sağlanması kritik önem taşır. Ürününüzü bir web sitesi olarak sunmak isterseniz, AWS, Google Cloud ve Hosting siteleri gibi klasik barındırma hizmetlerinden yararlanabilirsiniz. Mobil uygulama geliştirmek için ise, iOS veya Android platformlarında native uygulamalar geliştirip, App Store ve Google Play üzerinden yayınlama sürecini takip edebilirsiniz.
Son olarak, ürününüz yayına girdikten sonra kullanıcı geri bildirimlerini, performans verilerini ve API çağrılarından gelen yanıtların istikrarını sürekli olarak izlemeli, gerekirse prompt optimizasyonları ve hata düzeltmeleri ile ürününüzü güncellemelisiniz. Böylece, LLM kullanarak, sağlam ve kullanıcı dostu bir ürün ortaya koyabilirsiniz.
Peki LLM’ler nasıl çalışıyor ki bizim onu hizaya sokmamız gerekiyor?
Büyük dil modelleri yani LLM’ler. Bu modeller, insan dilini anlayabilir ve konuşabilir duruma gelmenin ötesinde, cümle içindeki ince nuansları dahi kavrayabilir. Bunu da genellikle “Transformer” adı verilen bir mimari sayesinde gerçekleştirirler. Transformer’lar, özellikle metin içindeki kelime (veya alt kelime parçacıkları) ilişkilerini güçlü bir şekilde modelleyerek, bir sonraki token’ı (yani kelime ya da kelime parçasını) olasılıksal olarak tahmin etmeye odaklanır.
Transformer yapısı genel anlamda üç farklı şekilde karşımıza çıkar:
Bir metni ya da başka bir veri türünü (örneğin görselden elde edilen metni) alır, yoğun bir temsil veya “embedding” olarak çıktı verir. “Embedding”, kelimelerin vektörel bir forma dönüştürülmesidir. Her bir boyutu (dim) model tarafından öğrenilmiş bir parametreye denk gelir ve kelimeler arasındaki ilişkileri, cümle bağlamını anlamaya yardımcı olur.
Örnek olarak Google’ın BERT modeli, tamamen bir “encoder” mimarisine dayanır ve text sınıflandırma, semantic arama gibi görevlerde kullanılır.
Modelin asıl çıktı ürettiği kısımdır. Encoder’dan gelen (veya kendi içinden ürettiği) embedding’leri alır ve yeni token’lar üretir. Yani metnin devamını yazar, soru-cevap yapar veya komutları yerine getirir. Örneğin GPT-4, Llama 3, DeepSeek-R1 gibi modeller “decoder-only” yaklaşımıyla çalışır.
Encoder ve Decoder’ın birleşik kullanıldığı bir yapı. Encoder gelen metni temsil eder, Decoder ise bu temsili kullanarak çıktı oluşturur. Örnek: T5 ve BART modelleri, girdi metnini özetlemek, dönüştürmek veya başka bir dile çevirmek gibi görevlerde kullanılır.
LLM’ler, metni sayılar dizisine (embedding’lere) çevirerek anlamlandırır. Örneğin “Selam ben mikail” cümlesini token’lara bölüp her token’ı bir vektöre dönüştürmek mümkündür:
# "Selam": [0.12, 0.35, -0.47, 0.88]
# "ben": [0.77, -0.33, 0.12, 0.56]
# "mikail":[0.19, 0.66, -0.23, 0.45]
[
[0.12, 0.35, -0.47, 0.88],
[0.77, -0.33, 0.12, 0.56],
[0.19, 0.66, -0.23, 0.45]
]
Bu şekilde kelimeler, modelin öğrenebileceği matematiksel bir uzayda ifade edilir.
LLM’ler, otoregresif bir yapıda çalışırlar. Yani model, bir önceki adımdaki çıktıyı bir sonraki adımın girdisi olarak kullanır ve bu döngü, “EOS” (end-of-sequence) tahmin edilene kadar devam eder. Örneğin “Hi, I’m mikail.” cümlesi, tek seferde “Hi,” şeklinde üretilmez; her kelime ya da alt kelime (token) sırasıyla tahmin edilir.
Token kavramı, kelimenin tamamını veya alt parçalarını temsil eder.
Örnek: “Hi, I’m mikail.” → 7 token (bazı modellerde farklılık gösterebilir).
LLM’ler ile konuşurken aslında kocaman bir prompt oluşturuyoruz; bu prompt, kullanıcı ve model arasında geçen her etkileşimi bir araya getiriyor. Kullanıcı her yeni mesaj yazdığında, önceki mesajlarla birleştirilmiş büyük bir metin (prompt) haline geliyor. Model ise bu metnin tamamını baştan sona okuyor ve bir sonraki cevabı oluşturuyor.
Chatbotlarda ise bu süreç, kullanıcıdan gizlenerek arka planda “mesaj alışverişi” (user, assistant, system vb. rollerde) olarak gösteriliyor. Böylece kullanıcı, sadece kendi yazdığı mesajları ve modelin yanıtlarını görüyor. Ancak perde arkasında, modelin her defasında “geçmiş konuşmaları + yeni mesajı” tekrar okuduğunu bilmekte fayda var.
Kullanıcı (User) ve model (Assistant) arasındaki mesaj alışverişini düzenleyen, modele özgü special token’ları (özel tokenlar) gizleyerek yönetmeyi sağlayan yapılardır. Bu sayede, kullanıcıdan gelen prompt’u arka planda modele uygun biçimde dönüştürür; modelden gelen yanıtı da kullanıcıya sunmadan önce düzenler.
Her modelin kendine ait kuralları ve kısıtlamaları olduğu için, chat template’ler bu kurallara uyacak şekilde prompt’ları şekillendirir. Örneğin, bazı modeller “system”, “user” ve “assistant” rolleriyle çalışırken, bazılarında <|im_start|> veya <eot_id> gibi farklı formatlar bulunur.
Konuşma boyunca bu rollerle ilerlenir ve “chat template” geçmiş konuşmaları koruyarak her seferinde modele güncel bir prompt olarak gönderir.
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face<|im_end|>
<|im_start|>user
I need help with my order<|im_end|>
<|im_start|>assistant
I'd be happy to help. Could you provide your order number?<|im_end|>
<|im_start|>user
It's ORDER-123<|im_end|>
<|im_start|>assistant<|im_end|><|begin_of_text|><|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
Today Date: 10 Feb 2025
<|eot_id|><|start_header_id|>user<|end_header_id|>
I need help with my order<|eot_id|><|start_header_id|>assistant<|end_header_id|>
I'd be happy to help. Could you provide your order number?<|eot_id|><|start_header_id|>user<|end_header_id|>
It's ORDER-123<|eot_id|><|start_header_id|>assistant<|end_header_id|>Daha önce bahsettiğimiz gibi, LLM’lerin kullandığı özel tokenlar, konuşmanın veya metnin bittiğini belirtmek gibi işlevler üstlenir. Her modelin kendine ait bir EOS (End of Sequence) veya benzer adla anılan token’ı bulunur. Aşağıdaki tabloda, farklı LLM’lerin sonlandırma (EOS) token’larına örnekler görebilirsiniz:
| Model | Provider | EOS Token | Functionality |
|---|---|---|---|
| GPT4 | OpenAI | <endoftext> | End of message text |
| Llama 3 | Meta (FAIR) | <eot_id> | End of sequence |
| Deepseek-R1 | DeepSeek | <end_of_sentence> | End of message text |
| SmolLM2 | Hugging Face | <lm_end> | End of instruction or message |
| Gemma | <end_of_turn> | End of conversation turn |
Bu token farklılıkları, modelin tokenizer ayarlarında (örneğin tokenizer_config.json) tanımlanır.
Bu tokenlar, chat template aşamasında veya tokenizasyon sürecinde prompt’a eklenir ve modelin ne zaman durması gerektiğini belirler.
Base model’in instruct modele dönüşümü, çoğunlukla “chat template” benzeri yapıların devreye sokulmasıyla olur. Burada system, user ve assistant rolleri belirginleştirilir ve modelin kullanıcıya nasıl yanıt vermesi gerektiği tanımlanır. ChatML gibi formatlar bu ayrımı netleştirmeye yardımcı olur.
Chat template'ler genellikle Jinja2 gibi şablonlama motorlarıyla hazırlanır ve mesaj dizisi, modelin beklediği formata dönüştürülür:
{% raw %}{% for message in messages %}
{% if loop.first and messages[0]['role'] != 'system' %}
<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face
<|im_end|>
{% endif %}
<|im_start|>{{ message['role'] }}
{{ message['content'] }}<|im_end|>
{% endfor %}{% endraw %}Örnek mesaj dizisi:
messages = [
{"role": "system", "content": "You are a helpful assistant focused on technical topics."},
{"role": "user", "content": "Can you explain what a chat template is?"},
{"role": "assistant", "content": "A chat template structures conversations..."},
{"role": "user", "content": "How do I use it ?"},
]Şablon uygulanınca:
<|im_start|>system
You are a helpful assistant focused on technical topics.<|im_end|>
<|im_start|>user
Can you explain what a chat template is?<|im_end|>
<|im_start|>assistant
A chat template structures conversations...<|im_end|>
<|im_start|>user
How do I use it ?<|im_end|>Not: Transformers gibi popüler kütüphaneler, bu sohbet şablonlarını tokenizasyon sürecine entegre ederek, kullanımınızı kolaylaştırır. Kod içinde ise benzer bir yaklaşımla, gelen mesajları modele uygun formata dönüştürebilirsiniz:
messages = [
{"role": "system", "content": "You are an AI assistant with access to various tools."},
{"role": "user", "content": "Hi !"},
{"role": "assistant", "content": "Hi human, what can help you with ?"},
]
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct")
rendered_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
Bu şekilde, "prompt" hazırlama ve çıktıları düzenleme işini koda gömerek, kullanıcıya daha akıcı bir sohbet deneyimi sunulabilir.
Transformer'ların en önemli özelliği "attention"dır. Bir cümledeki her kelime, aynı öneme sahip değildir. "Attention" mekanizması, cümledeki hangi kelimelerin bağlam açısından daha kritik olduğunu belirleyerek, üretilecek yeni token'ların olasılıklarını bu kritik kelimelere göre ayarlar. LLM'lerin bir "context window" veya "attention span" sınırı vardır; yani model, en fazla bu kadar token'lık bir diziyi göz önünde bulundurarak yeni token üretir.
LLM'e ne verirseniz, ona göre bir çıktı alırsınız. Dolayısıyla, modelin üreteceği metni yönlendirmek istiyorsanız, prompt adı verilen girdi metninizi özenle hazırlamalısınız. Hedefiniz netse, modelin doğru ve tutarlı sonuç verme olasılığı artar. Prompt yazmak ile ilgili ayrıntılı bir makalem daha var okumak isterseniz → Yapay Zekayı Nasıl Daha İyi Kullanırım?
LLM'ler, devasa miktarda veriyi (internet metinleri, kitaplar, vs.) kullanarak "self-supervised" veya "maskeli dil modelleme" yöntemleriyle eğitilir. Model, bu aşamada "bir sonraki token nedir?" sorusunu cevaplamayı öğrenir. Böylece dilin yapısını, gramerini ve bağlam ilişkilerini içselleştirir. Bu aşamaya pre-training denir.
Pre-training sonrasında model, belirli bir göreve (soru-cevap, çeviri, kod üretimi vb.) uyarlanmak için fine-tuning aşamasına girer. Bazı modeller, kullanıcıyla etkileşim kurabilmek için ek olarak "instruct fine-tuning" veya "RLHF (Reinforcement Learning from Human Feedback)" gibi yöntemlerden geçer.
Özetle, LLM'lerin çalışma prensibi, devasa veri setlerinden öğrendikleri dil kalıpları aracılığıyla bir sonraki token'ı tahmin etmekten ibarettir. Bu basit gibi görünen mekanizma, dikkat (attention) ve embedding gibi tekniklerle birleştiğinde, metin anlama ve üretme konusunda şaşırtıcı derecede güçlü sonuçlar verir. İşte bizim, bu modelden aldığımız çıktıyı doğru kullanmak için "prompt" optimizasyonları yapmamız, çıktıyı temizlememiz ve ürünümüze uygun formatta sunmamız gerekir. Aksi takdirde, LLM'in varsayılan tahmin süreçleri, beklentilerimizi karşılamayan sonuçlar üretebilir.
LLM'lerin verimli ve isabetli çıktılar üretmesi, modelinize sağladığınız girdilerin kalitesiyle doğrudan ilişkilidir. Yukarıda LLM'lerin çalışma prensiplerini ve uygulamada nasıl fayda sağlayabileceğimizi inceledik. Ancak, modelin eğitildiği veriler geçmişe dayalı olduğundan, güncel sorgulara yanıt verirken halüsinasyon riski ortaya çıkabiliyor.
Örneğin, "Bugün İstanbul'da hava nasıl?" gibi bir soruya, geçmiş verilerle eğitilmiş bir LLM yalnızca varsayımlarla yanıt verebilir. Fakat, en güncel hava durumu bilgisini (örneğin, bir hava durumu API'sinden alınan veriyi) modele eklediğinizde, yanıtlarınız daha doğru ve güvenilir hale gelecektir. Bu strateji, LLM'lerin gerçek zamanlı verilere dayalı olarak doğru çıktılar üretebilmesinde kritik bir rol oynar.
Anthropic'in "Building Effective Agents" çalışmasında da vurgulandığı üzere, etkili bir agent oluşturmak için yalnızca modelin temel yeteneklerini kullanmak yetmez; aynı zamanda doğru bilgiyi, gerekli toolları ve belirleyici kuralları da entegre etmek gerekir. Bu yaklaşımın temel prensiplerini özetleyerek LLM'leri nasıl hizaya sokabileceğimizi daha yakından inceleyeceğiz ancak öncesinde workflow ve agent tanımlarını yapalım.
Workflow, LLM'lerin (Büyük Dil Modelleri) ve türetilen sistemlerin verimli ne tutarlı bir şekilde çalışabilmesi için tasarlanmış bir dizi adım, kontrol mekanizması ve entegrasyon yöntemidir. Bu yapı, temel modelin ötesine geçerek retrieval (veri çekme), araçlar (API istekleri gibi) ve hafıza gibi bileşenlerle desteklenir. Böylece, model yalnızca metin üretmekle kalmaz; aynı zamanda dinamik veri işleme, güncel bilgilere erişim ve sistematik görev yönetimi de gerçekleştirebilir. Ancak bu yaklaşımda esneklik geri planda kalır. Tutarlılık ile esneklik takas edilir.
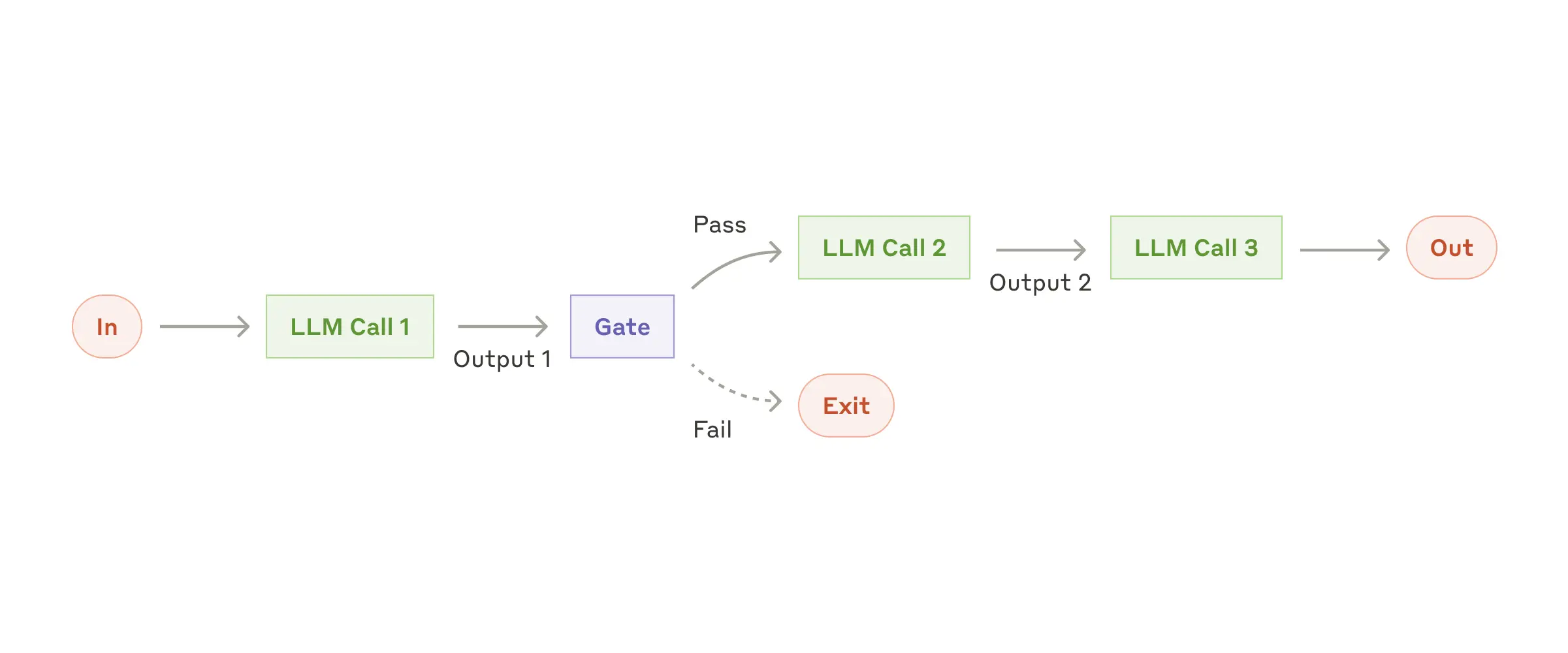
Prompt Chaining, verilen bir görevin birbirini izleyen adımlara bölünerek her adımın çıktısının bir sonraki adımın girdisi haline getirilmesi prensibine dayanır. Bu yöntemde, programlanabilir checkpoint'ler (Gate) kullanılarak sürecin doğru ilerleyip ilerlemediği kontrol edilir. Adımlara bölünmüş görevler, her bir alt adımın ayrı ayrı LLM tarafından işlenmesiyle tutarlılığı artırır; ancak bu durum işlem süresinde belirli bir gecikmeye yol açabilir.
Örnekler:
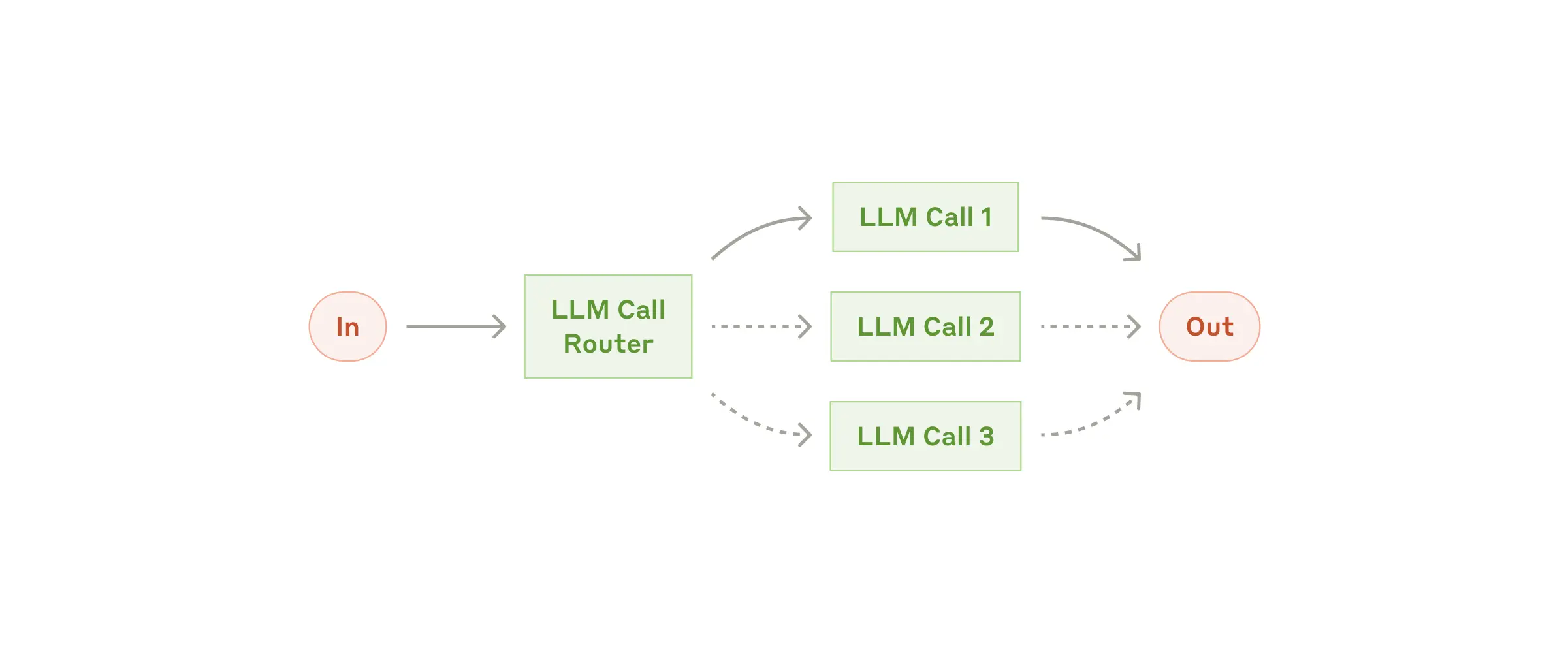
Routing yöntemi, gelen isteklerin bir sınıflandırma LLM'i tarafından analiz edilip, hangi model veya iş akışının uygun olduğunun belirlenmesini sağlar. Bu sayede, farklı türdeki görevler, kendi özelliklerine uygun alt süreçlere yönlendirilir ve alakasız model çağrılarının önüne geçilir.
Örnekler:
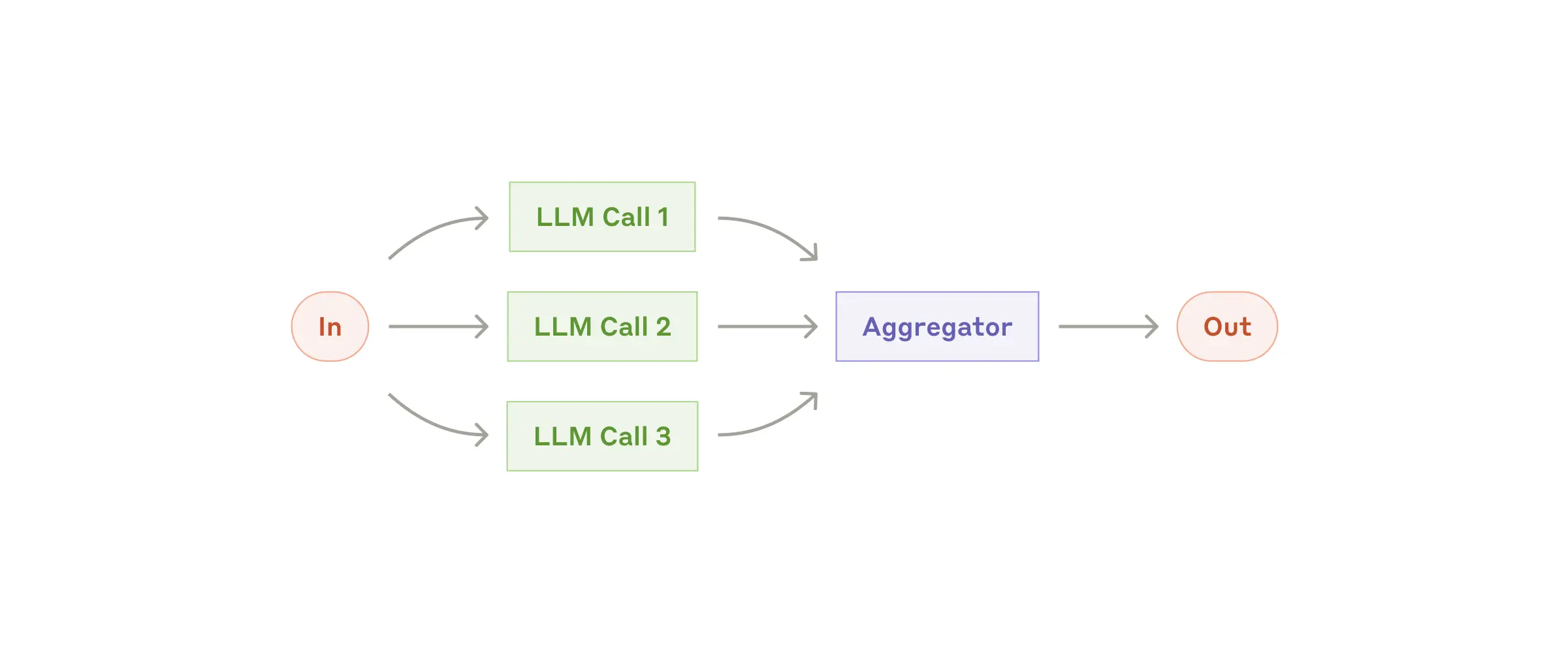
Parallelization, bir görevin alt parçalara bölünüp, bu parçaların aynı anda birden fazla LLM tarafından paralel olarak işlenmesi sürecidir. İşlenen alt görevler, daha sonra birleştirilerek nihai sonuç ortaya çıkarılır. Bu yöntem, her bir alt göreve ayrı dikkat gösterildiği için genellikle daha yüksek performans ve hız sağlar.
Örnekler:
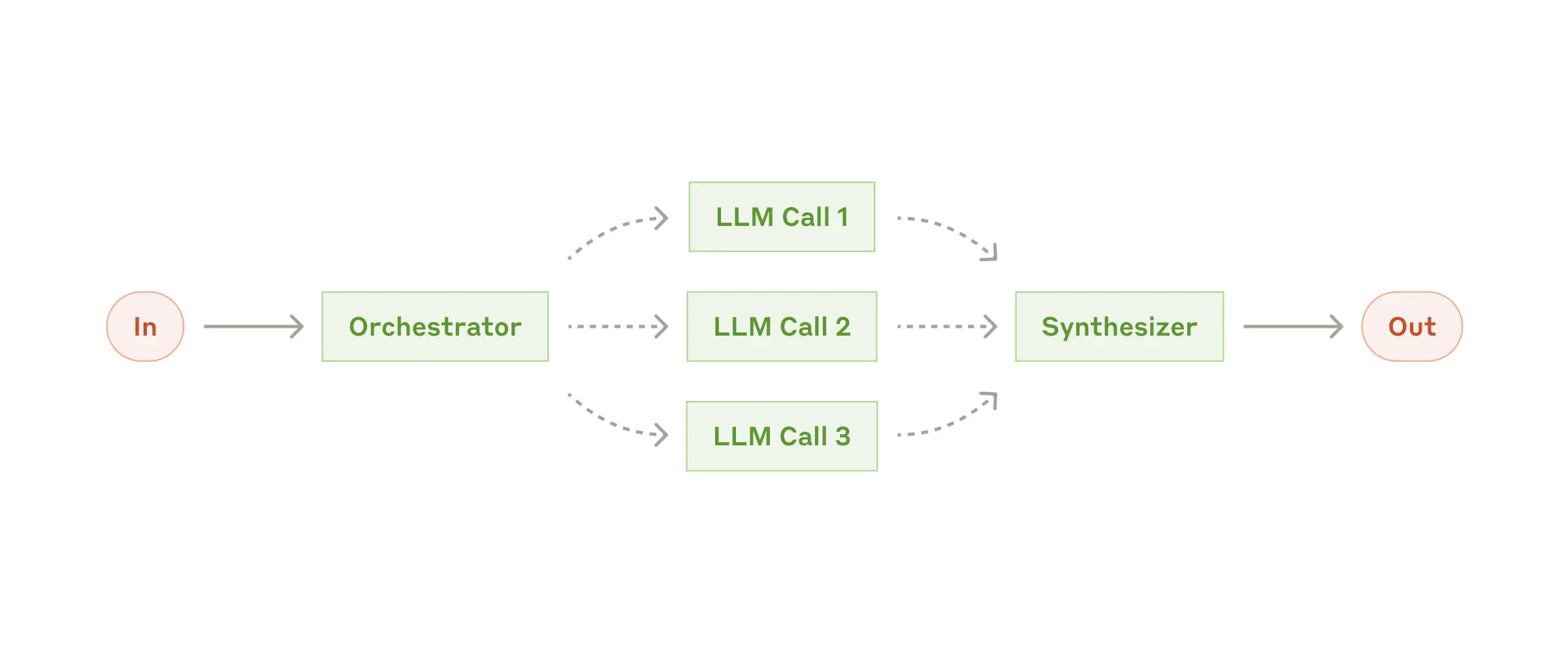
Bu iş akışında, ana LLM gelen görevi dinamik olarak alt görevlere böler ve hangi worker LLM'in hangi bölümü çalıştıracağına karar verir. Worker'ların çıktıları, son aşamada bir Synthesizer LLM tarafından işlenip nihai sonuç oluşturulur. Bu yapı, özellikle alt görevlerin önceden tanımlanamadığı, girdiye göre esnek olarak belirlendiği karmaşık senaryolarda öne çıkar.
Örnekler:
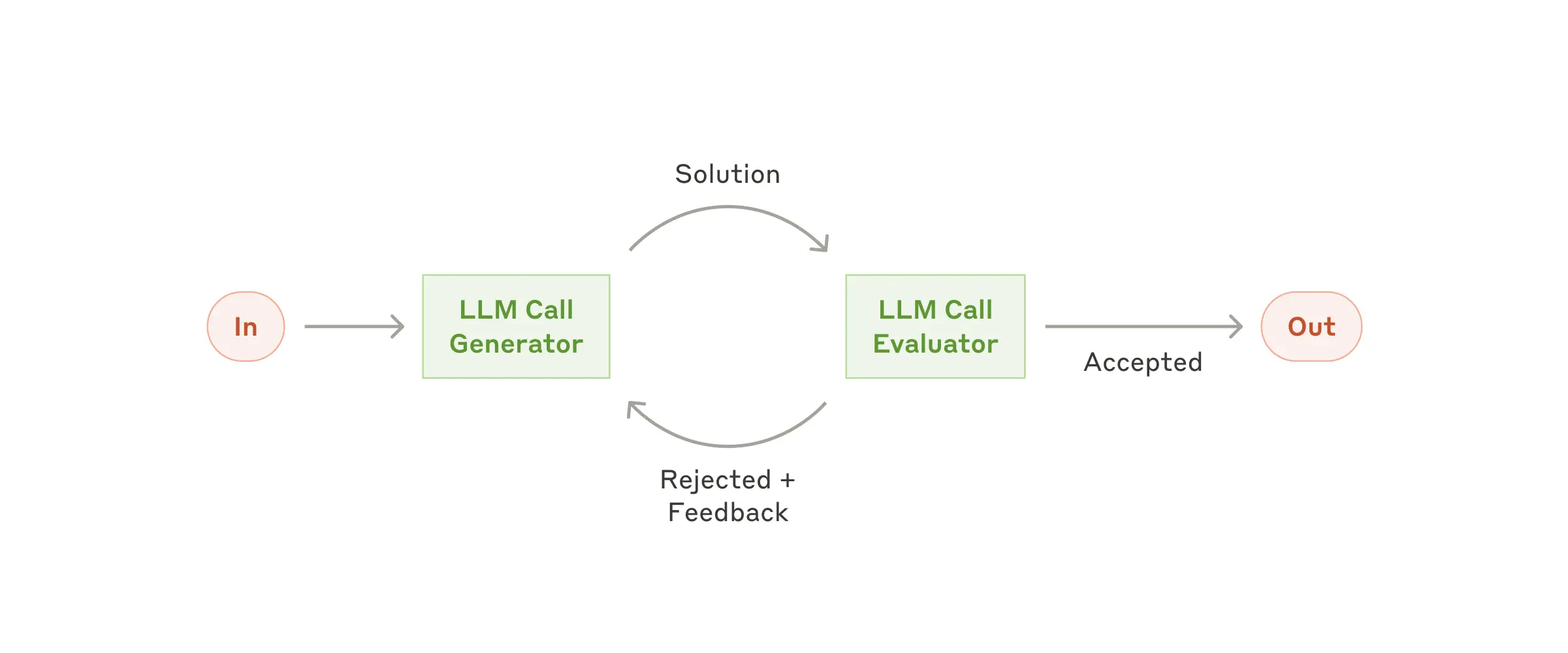
Evaluator - Optimizer yaklaşımında, bir LLM önce verilen girdiyi işleyip bir sonuç üretir; ardından bu sonuç, başka bir LLM tarafından belirlenmiş değerlendirme kriterlerine göre incelenir. Eğer sonuç istenen standartları karşılamıyorsa, geri bildirim sağlanır ve işlem tekrarlanır. Bu döngü, model çıktılarının kalitesinin iteratif olarak iyileştirilmesini sağlar.
Örnekler:
Bu workflow yaklaşımları, LLM'lerin ve agent sistemlerin karmaşık görevleri daha etkili ve esnek bir şekilde yerine getirmesine olanak tanır. Hangi yöntemin kullanılacağı, projenizin özel ihtiyaçlarına, görevlerin yapısına ve performans beklentilerine göre belirlenir.
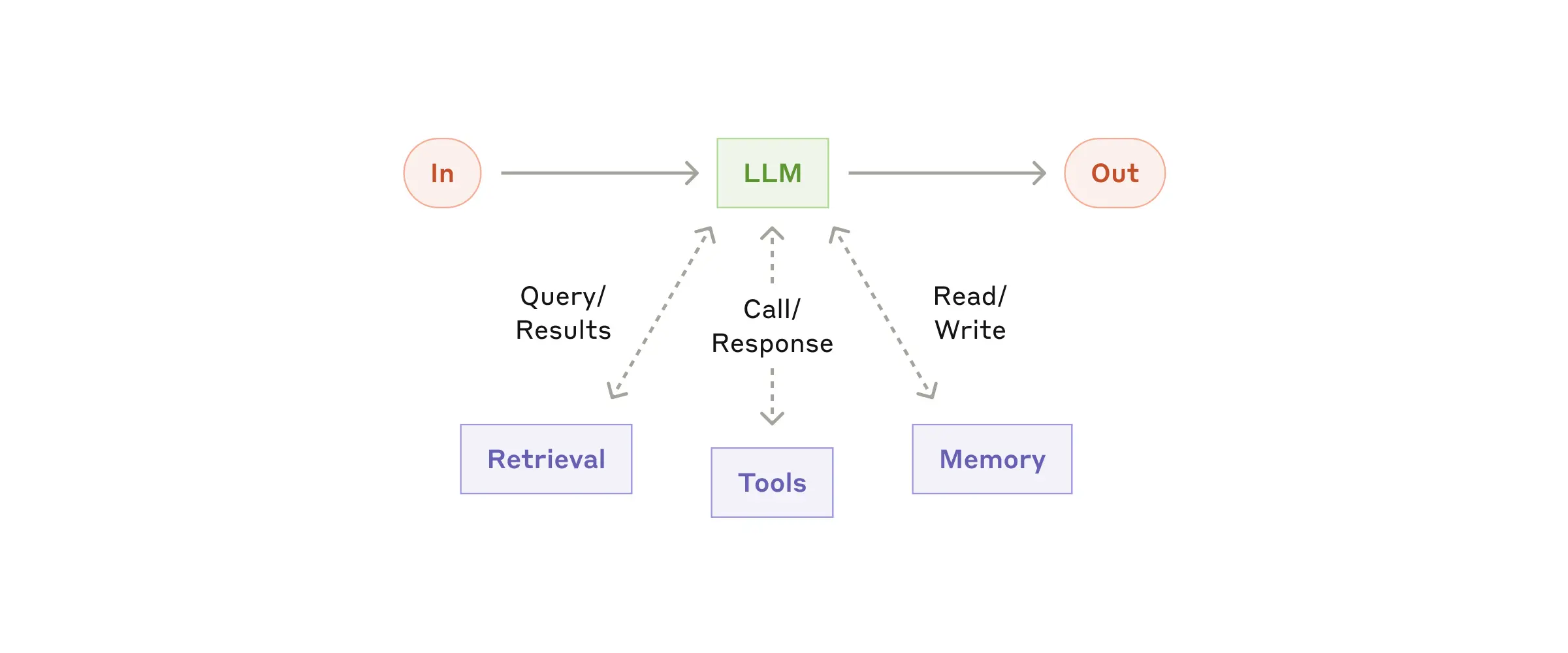
Artırılmış LLM, temel modelin yeteneklerini retrieval, tools (araçlar, API entegrasyonları) ve memory (hafıza) gibi ek bileşenlerle zenginleştirir. Böylece, modelin fonksiyonelliği genişler ve yalnızca geçmiş verilerle sınırlı kalmayıp, gerçek zamanlı veri işleyebilme kapasitesi kazanır. Sistem oluştururken kullanılan araçların ve kodun iyi dökümanlaştırılması uzun vadeli verimlilik için büyük önem taşır. Ayrıca, Anthropic tarafından sunulan Model Context Protocol (MCP) gibi yaklaşımlar, LLM'lere yapılan geliştirmeleri desteklemekte ve sistemin bağlamını iyileştirmektedir.
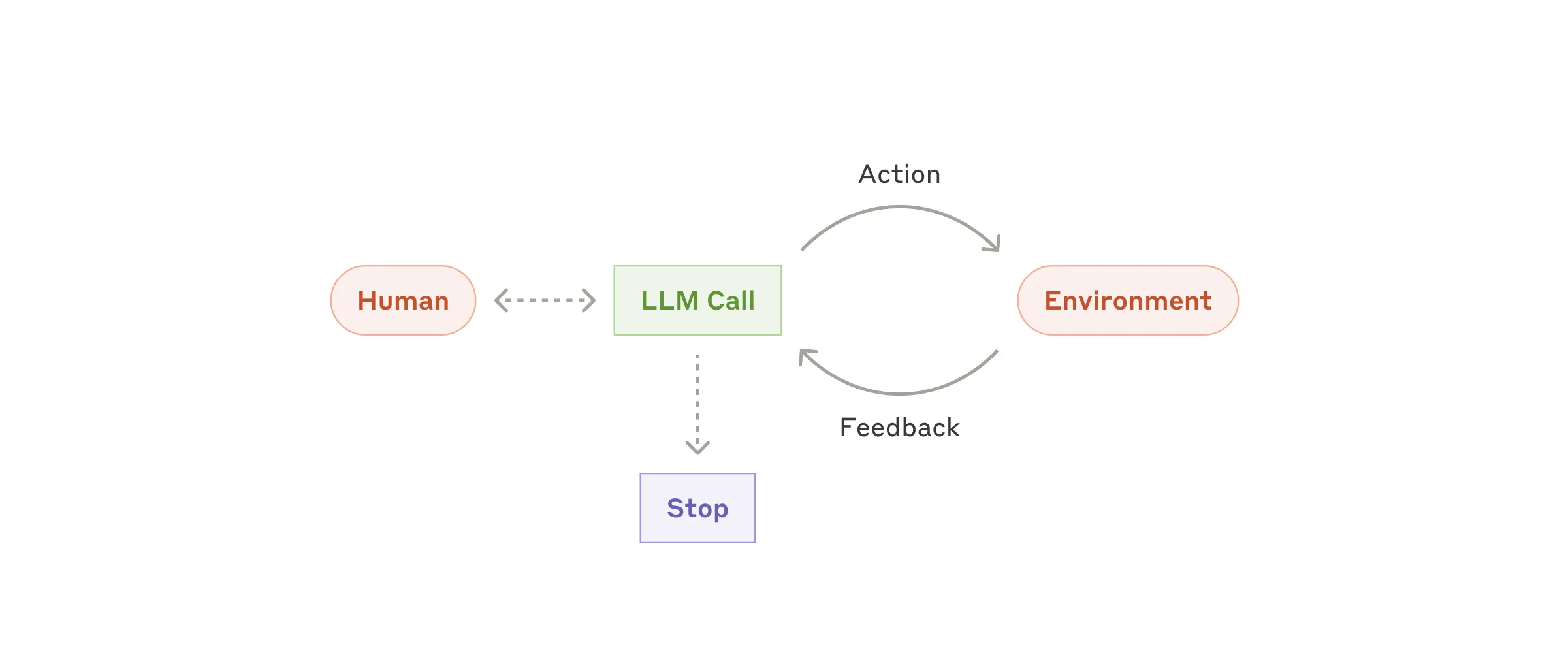
Agent, bir isteği alıp, muhakeme ederek ve plan yaparak, elindeki araçları kullanıp çevresiyle etkileşime giren akıllı sistemlerdir. Kısaca, agentlar doğal dil girdilerini işleyip, bu girdilere uygun aksiyonları alarak kullanıcıya yanıt veren dinamik asistanlardır. Aşağıdaki şemada, bir agentın çalışma prensibi özetlenmiştir:

Agentları iki temel bileşenden oluşan bir sistem olarak düşünebiliriz:
Örneğin, ChatGPT'nin resim çizme yeteneği, agent özelliklerinin bir örneğidir; yani elindeki araçları (bu durumda VLM – Vision Language Model) kullanarak belirli bir görevi yerine getirir.
Agentlar, genellikle LLM'ler (Büyük Dil Modelleri) kullanılarak inşa edilir; ancak gerektiğinde VLM gibi farklı modeller de entegre edilebilir. Temel çalışma mantıkları ise, aşağıdaki döngü ile özetlenebilir:
Bu Thought-Action-Observation (TAO) döngüsü, Agent'ların çevresel geri bildirimleriyle sürekli olarak uyum sağlamasına ve daha isabetli sonuçlar üretmesine olanak tanır.
Agentlar, doğrudan dış araçları (API'ler, hesaplama fonksiyonları, veri toplama araçları vb.) çağırabilecek yeteneğe sahip değildir; LLM'ler yalnızca metinle çalışır. Bu nedenle, dış araçların kullanılması için bir " agent" devreye girer. Süreç şu şekilde işler:
Örneğin, Python ile bir e-posta gönderme aracı şöyle tanımlanabilir:
def send_message_to(recipient, message):
"""Belirtilen alıcıya e-posta göndermek için kullanılır."""
...Ardından agent, şu şekilde bir komutla bu aracı devreye sokabilir:
send_message_to("Manager", "Can we postpone today's meeting?")Tool'ların (araçların) kalitesi, agent performansını doğrudan etkiler. İyi tanımlanmış araçlar, agent'ların karmaşık görevleri daha etkili bir şekilde yerine getirmesine olanak tanır.
Agentlar, doğal dil girdilerini anlayıp işleyebilen, içsel muhakeme (Thought) ve planlama süreçleriyle en uygun aksiyonu belirleyen, ardından araçlar (Tools) sayesinde çevresiyle etkileşime girerek sonuç üreten yapay zeka sistemleridir. Bu sistemler, kullanıcıya sanki LLM doğrudan aksiyon alıyormuş gibi akıcı bir deneyim sunar. Böylece, karmaşık görevler adım adım çözümlenir ve gerçek zamanlı geri bildirimlerle sürekli geliştirilebilir hale gelir.
Agent geliştirirken işleri kolaylaştıran frameworkleri kullanmak, ürün teslim hızını artırır; ancak, hata durumlarında debug sürecimiz uzayabilir. Eğer işin temel prensiplerini öğrenmeden doğrudan framework kullanmaya başlarsak, uygulamanın arka planında neler döndüğünü anlamak zorlaşır. Bu yüzden, önce temel kavramları öğrenip pekiştirdikten sonra framework’lere yönelmek uzun vadede daha sağlıklı sonuçlar verir.
Framework’lerin kullanımı, agent geliştirme sürecinde büyük avantajlar sunduğu kadar bazı dezavantajları da beraberinde getirir. Frameworkler sayesinde hazır bileşenler ve modüler yapı ile geliştirme hızı artarken, kod tekrarı azalır. Ancak, ek soyutlama katmanları nedeniyle hataların kaynağını tespit etmek zorlaşabilir.
Aşağıda, framework kullanımı ile native (sıfırdan) geliştirme arasındaki farkları özetleyen bir tablo bulabilirsiniz:
| Özellik | Framework Kullanımı | Native Geliştirme |
|---|---|---|
| Geliştirme Hızı | Hazır bileşenler ve modüler yapı sayesinde hızlı prototip oluşturma imkanı sağlar. | Sıfırdan kod yazıldığı için geliştirme süreci daha uzun ve zahmetlidir. |
| Hata Ayıklama | Soyutlama katmanları nedeniyle hataların kaynağını bulmak zorlaşabilir. | Düşük seviyede kontrol, hataların detaylı incelenmesini kolaylaştırır. |
| Esneklik & Kontrol | Framework'ün sunduğu yapı ve kalıplara bağlı kalınır; özelleştirme imkanı sınırlı olabilir. | Tam kontrol sağlanır; ihtiyaçlara göre her şey özelleştirilebilir. |
| Öğrenme Eğrisi | Başlangıçta kolaylık sağlasa da, framework’ün işleyiş mekanizmalarını derinlemesine öğrenmek gerekebilir. | Temel prensiplerden başlamak zaman alıcı olabilir, ancak kavrayış güçlenir. |
| Performans | Ek soyutlama katmanları bazen ek performans maliyeti getirebilir. | Optimizasyon ve performans iyileştirmeleri daha doğrudan uygulanabilir. |
| Topluluk & Destek | Geniş kullanıcı ve geliştirici toplulukları sayesinde dokümantasyon ve destek bulunabilir. | Kendi çözümlerinizi üretmek gerekebilir; topluluk desteği sınırlı olabilir. |
Ayrıca, AI agent geliştirme için tercih edilebilecek bazı popüler framework örnekleri şunlardır:
Şunu da eklemeden geçemeyeceğim. Agent geliştirirken çok karmaşık işlemler yapılmamaktadır. Framework'e çokta ihtiyacınız kalmayabilir. Birazdan örneklerde de bunu göreceksiniz.
Sonuç olarak, agent geliştirme sürecinde framework kullanmak, geliştirme hızını artırırken temel kavramların öğrenilmesi ve sistemin arka planının anlaşılması açısından native yaklaşımlar da göz ardı edilmemelidir.
Bu işte çok diyecek bir şey yok. Gemini kullanın. Neredeyse bütün modellerinde 1M token'a kadar ücretsiz kullanım var. Ayrıca 1M token aşımında da fiyatlar çok uygun. Google Gemini Ücretler
Google üyeliğiniz ile Google AI Studio giriş yapın. Daha sonra New Chat adresine girin. Orda sol üst köşede "Get API key" butonuna tıklayın. Daha sonra "Create API key" butonuna tıklayın. Eğer hesabınız Google Cloud Console ile eşleştirilmişse bir "billing" hesabına bağlamanızı ister. Yoksa doğrudan api key oluşturma ekranı çıkar. Oluşan key'i kopyalayın. Örnek kullanım için şu öğreticiye gidin -> Google API istek örneği